데이터 웨어하우스와 SQL과 데이터분석
주요 메모 사항
AWS Redshift
- Cluster 생성
관계형 데이터베이스 예제 - 웹서비스 사용자/세션 정보
- 사용자 ID : 보통 웹서비스에서는 등록된 사용자마다 부여하는 유일한 ID
- 세션 ID : 세션마다 부여되는 ID
- 세션 : 사용자의 방문을 논리적인 단위로 나눈 것
- 사용자가 외부 링크를 타고 오거나 직접 방문해서 올 경우 세션 생성
- 사용자가 방문후 30분간 interaction이 없다가 뭔가를 하는경우 새로 세션 생성
- 즉, 하나의 사용자는 여러개의 세션을 가질 수 있음
- 보통의 세션의 경우 세션을 만들어낸 접점을 채널이란 이름으로 기록해둠, 세션이 생긴 시간도 기록
- 마케팅 관련 기여도 분석을 위함
- 이 정보를 기반으로 다양한 데이터 분석과 지표 설정이 가능
- 마케팅 관련, 사용자 트래픽 관련
- DAU, WAU, MAU등의 일주,월 별 Active User (기간동안 방문한 사람) 차트
- Marketing Channel Attribution 분석, 어느 채널에 광고를 하는 것이 가장 효과적인가?
다음 예제로 3개의 세션이 생성되는 것을 이해
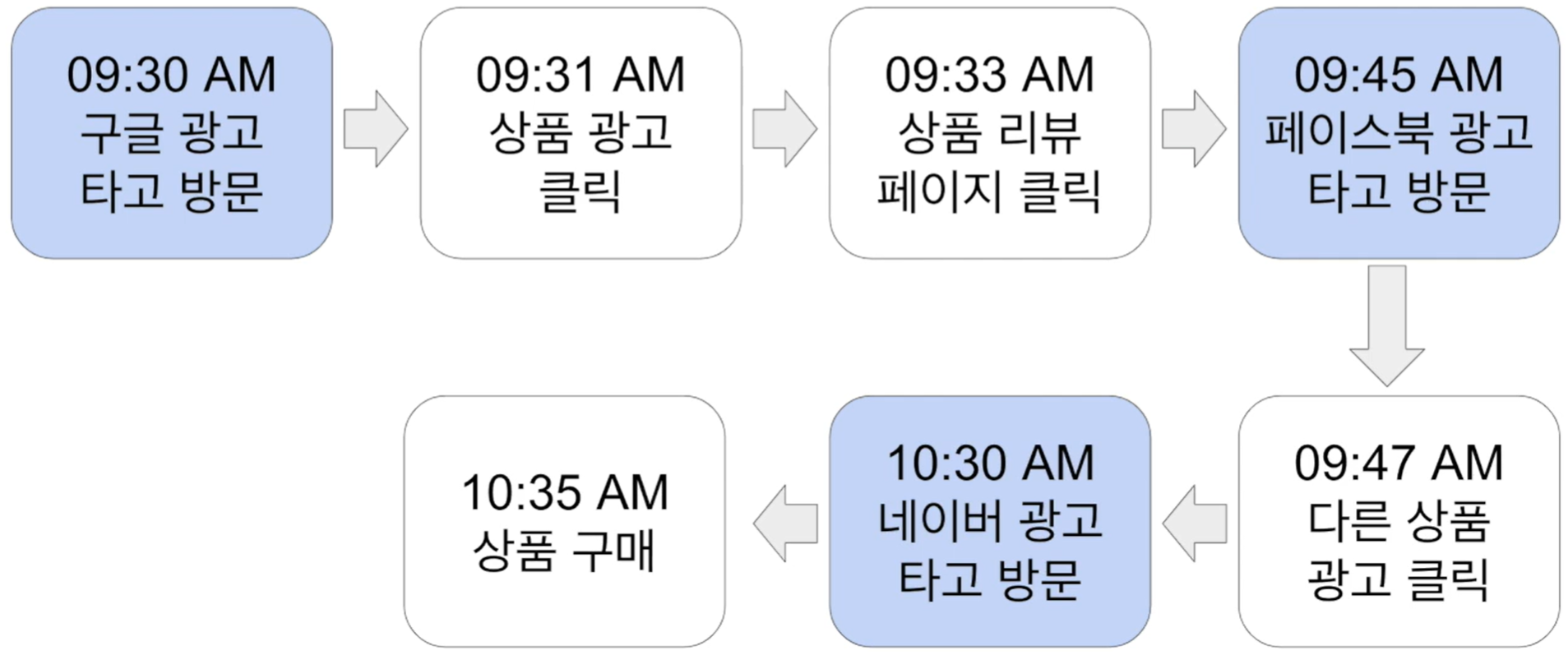
데이터베이스와 테이블



Redshift 중심으로 DDL과 DML
SQL 기본
- SQL 키워드는 대문자를 자용한다던지 하는 나름대로의 포맷팅이 필요
- 팀 프로젝트라면 팀에서 사용하는 공통 포맷이 필요
- 테이블 / 필드 이름의 명명규칙을 정하는 것이 중요
- 단수형 vs 복수형 -> User vs Users
- _ vs CamelCasing -> user_sseion_channel vs UserSessionChannel
SQL DDL
CREATE TABLE
- Primary key 속성을 지정할 수 있으나 무시됨
- Primary key uniqueness -> 이전 포스팅에서도 기록했음
- Big Data 데이터 웨어하우스에서는 지켜지지 않음 (Redshift, Snowflake, BigQuery)
- CTAS : CREATE TABLE table_name AS SELECT vs CREATE TABLE and then INSERT
CREATE TABLE raw_data.user_session_channel (
userid int,
sessionid varchar(32) primary key, // 무시됨
channel varchar(32)
)
CREATE TABLE raw_data.session_timestamp (
sessionid varchar(32) primary key, // 무시됨
ts timestamp
);
DROP TABLE
- DROP TABLE table_name; -> 없는 테이블을 지우려고 하면 에러를 냄
- DROP TABLE IF EXISTS table_name; -> 이와 같은 방식으로 사용
- vs DELETE FROM -> 조건에 맞는 레코드들을 지움 (테이블 삭제 X)
ALTER TABLE
- 새로운 컬럼 추가 -> ALTER TABLE 테이블이름 ADD COLUMN 필드이름 필드타입;
- 기존 컬럼 이름 변경 -> ALTER TABLE 테이블이름 RENAME 현재필드이름 to 새필드이름;
- 기존 컬럼 제거 -> ALTER TABLE 테이블이름 DROP COLUMN 필드이름;
- 테이블 이름 변경 -> ALTER TABLE 현재테이블이름 RENAME to 새테이블이름;
SELECT
- SELECT ~ FROM TABLE
- GROUP BY, ORDER BY 등 다양한 사용법이 많이 있으니 생략
SQL DML
레코드 수정 언어
- INSERT INTO : 테이블에 레코드 추가
- UPDATE FROM : 테이블 레코드의 필드 값 수정
- DELETE FROM : 테이블에서 레코드 삭제
실습 이전에 앞서 기억할 점
- 현업에서 꺠끗한 데이터란 존재하지 않음
- 할상 데이터를 믿을 수 있는지 의심
- 실제 레코드를 몇개 살펴보는 것, 만한 것이 없음
- 데이터 일을 한다면 항상 데이터의 품질을 의심하고 체크하는 버릇이 필요
- 중복된 레코드들 체크하기
- 최근 데이터의 존재 여부 체크
- Primary key uniqueness가 지켜지는지 체크
- 값이 비어있는 컬럼들이 있는지 체크
- 위의 체크는 코딩의 unit test 형태로 만들어 매번 쉽게 체크해볼 수 있음
- 어느 시점이 되면 너무나 많은 테이블들이 존재하게 됨
- 회사 성장과 밀접한 관련
- 중요 테이블드링 무엇이고 그것들의 메타 정보를 잘 관리하는 것이 중요해짐
- 그 시점부터는 Data Discovery 문제들이 생겨남
- 무슨 테이블에 내가 원하고 신뢰할 수 있는 정보가 들어있나?
- 테이블에 대해 질문을 하고 싶은데 누구에게 질문해야하나?
- 이문제를 해결하기 위한 다양한 오픈소스와 서비스들이 출현
- DataHub(LinkedIn), Amundsen(Lyft) ~~~
- Select Star, DataFrame, ~~~
Colab 에서 Redshift Cluster로 SQL 실습
공부하며 어려웠던 내용
어려웠던 내용은 없었으나 aws 에서 Redshift Cluster 생성하는데 조금 막혔었다.
강의에서는 구AWS라서 그런지 Redshift를 클릭했을 때 그냥 들어가지는데, 금일 기준으로 Redshift serverless 기능이 나오면서 자동으로 다른 대시보드로 이동되었다. 여기에서 Cluster만 생성하는 페이지로 들어가는 것을 찾다가 시간을 좀 낭비했다... -> 학부때 Azure로 프로젝트 할 때 마다 머리가 아팠는데 Azure보다는 양반인 것 같다. 그리고 google에 정보도 많다!!
'프로그래머스 데브코스-데이터 엔지니어 > TIL(Today I Learned)' 카테고리의 다른 글
| 05/11 24일차 데이터 웨어하우스와 SQL과 데이터분석 (4) (0) | 2023.05.11 |
|---|---|
| 05/10 23일차 데이터 웨어하우스와 SQL과 데이터분석 (3) (1) | 2023.05.10 |
| 05/08 21일차 데이터 웨어하우스와 SQL과 데이터분석 (1) (0) | 2023.05.08 |
| 05/05 20일차 프로젝트 5일차 마지막 날 (0) | 2023.05.06 |
| 05/04 19일차 프로젝트 4일차 (0) | 2023.05.06 |