DE와 데이터 웨어하우스
주요 메모 사항
데이터 조직의 비전
- 신뢰할 수 있는 데이터를 바탕으로 부가가치 생성
- Data is the new oil?
- 데이터의 중요성을 강조하니 데이터 팀도 회사에서 인정을 받는다?
데이터 조직이 하는 일(1)
- 고품질 데이터를 기반으로 의사 결정권자에게 입력 제공
- 결정 방향 이라고 부르기도 함
- 데이터를 고려한 결정을 가능하게 해줌 ->데이터 기반 결정 (Data driven Decisions)
- 예를 들면 데이터 기반 지표 정의, 대시보드와 리포트 생성 등을 수행
- 고품질 데이터를 기반으로 사용자 서비스 경험을 개선 혹은 프로세스 최적화
- 머신 러닝과 같은 알고리즘을 통해 사용자의 서비스 경험을 개선
- 예) 개인화를 바탕으로한 추천과 검색기능 제공
- 머신 러닝과 같은 알고리즘을 통해 사용자의 서비스 경험을 개선
-
- 공장이라면 공정 과정에서 오류를 최소화하는 일을 수행
데이터의 흐름, 데이터 팀의 발전단계
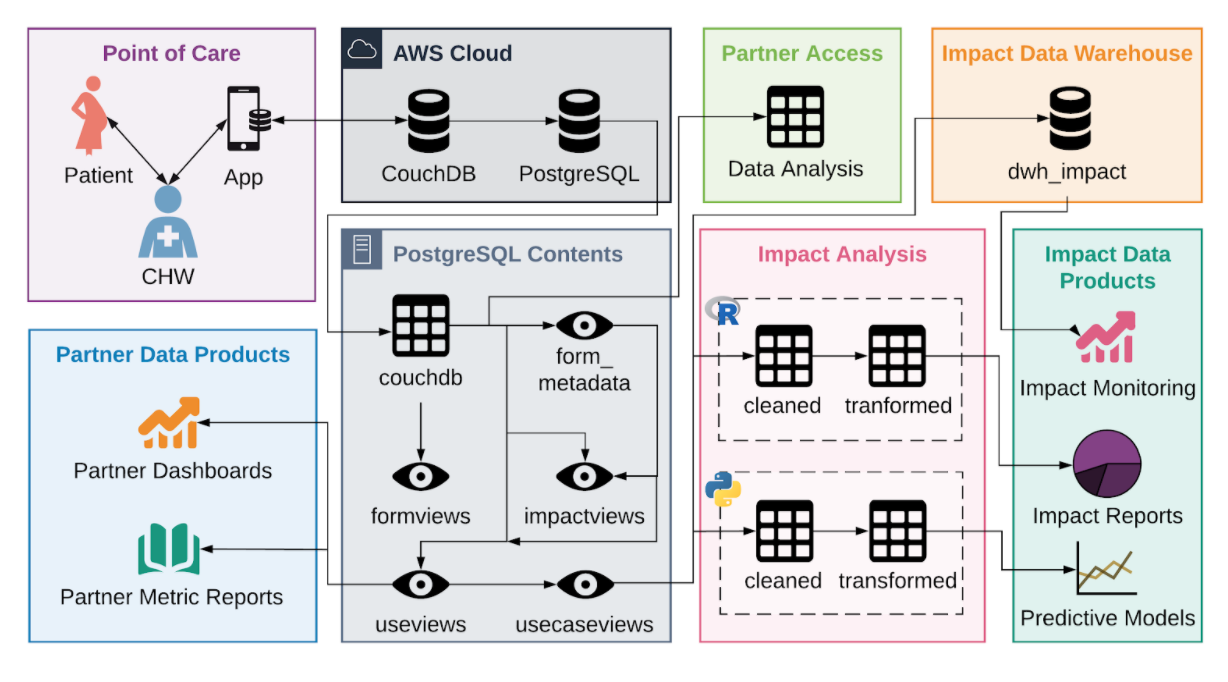
- 해당 이미지의 기입된 기술이 아닌 flow를 이해하기 위한 이미지
- 위와 같이 만들어 진다면 이상적인 flow
- 하지만 일반적으로 데이터 분석 -> 데이터 과학 적용 을 진행하다가 데이터 인프라의 필요성을 느끼게 됨
데이터 웨어하우스
- 회사에 필요한 모든 데이터를 모아놓은 중앙 데이터 베이스 (SQL 데이터베이스)
- 크기가 커진다면 다음 중 하나를 선택
- AWS Redshift, GCP BigQuery
- 스노우플레이크(Snowflake)
- 오픈소스 기반의 하둡(Hive/Presto)/Spark
- 이 모두 SQL을 지원
- 중요 표인트는 프로덕션용 데이터베이스와 별개의 데이터베이스여야 한다는 점
- 데이터 웨어하우스의 구축이 진정한 데이터 조직이되는 첫 번쨰 스텝
ETL

- 다른곳에 존재하는 데이터를 가져다가 데이터 웨어하우스에 로드하는 작업
- Extract : 외부 데이터 소스에서 데이터를 추출
- Transform : 데이터의 포맷을 원하는 형태로 변환
- Load : 변환된 데이터를 최종적으로 데이터 웨어하우스로 적재
- 데이터 파이프라인이라고 부르기도 함
- 관련하여 가장 많이 쓰이는 프레임웍은 Airflow
- Airflow는 오픈소스 프로젝트로 파이썬 3 기반이며 Airbnb에서 시작
- AWS와 구글 클라우드에서도 지원
- ETL 관련 Saas(Software as a Service) 도 출현하기 시작 -> DE가 일이 너무 많아서 보완하기 위한 용도
- 흔한 데이터 소스의 경우 FiveTran, Stitch Data와 같은 SaaS를 사용하는 것도 가능
시각화 대시보드
- 보통 중요한 지표를 시간의 흐름과 함께 보여주는 것이 일반적
- 지표의 경우 3A(Accessible, Actionable, Auditable) 가 중요
- 중요 지표의 예: 매출액, 월간/주간 액티브 사용자 수, ...
- 가장 널리 사용되는 대시보드:
- 구글 클라우드의 룩커, Looker
- 세일즈포스의 태블로, Tableau
- 마이크로소프트의 파워 BI, Power Bi
- 오픈소스 아파치 수퍼셋 SuperSet
데이터 팀에는 누가 있는가?
- 작은 회사에서는 한 사람이 몇 개의 역할을 동시 수행하는 것이 일반적
- 데이터 엔지니어 DE
- 데이터 인프라 (데이터 웨어하우스와 ETL) 구축
- 데이터 분석가 DA
- 데이터 웨어하우스의 데이터를 기반으로 지표를 만들고 시각화 (대시보드)
- 내부 직원들의 데이터 관련 질문 응답
- 데이터 과학자 DS
- 과거 데이터를 기반으로 미래를 예측하는 머신러닝 모델을 만들어 고객들의 서비스 경험을 개선 (개인화 혹은 자동화 혹은 최적화)
- 기본적으로는 소프트웨어 엔지니어
- 파이썬이 대세. 자바 혹은 스칼라와 같은 언어도 아는 것이 좋음
- 데이터 웨어하우스 구축
- 데이터 웨어하우스를 만들고 이를 관리. 클라우드로 가는 것이 추세
- aws의 Redshift, GCP의 BigQuery, Snowflake
- 관련해서 중요한 작업중의 하나는 ETL코드를 작성하고 주기적으로 실행해주는 것
- ETL 스케줄러 혹은 프레임 웍이 필요 (Airflow 가 대세)
- 데이터 웨어하우스를 만들고 이를 관리. 클라우드로 가는 것이 추세
- 데이터 분석가와 과학자 지원
- 데이터 분석가, 데이터 과학자들과의 협업을 통해 필요한 툴이나 데이터를 제공해주는 것이 데이터 엔지니어의 중요한 역할 중의 하나
데이터 엔지니어가 알아야하는 기술
- SQL : 기본 SQL, Hive, Presto, SparkSQL
- 프로그래밍 언어 : 파이썬, 스칼라, 자바
- 데이터 웨어하우스 (Redshift / Snowflake / BigQuery)
- ETL / ELT 프레임웍 : Airflow, ....
- 대용량 데이터 처리 플랫폼 : Spark/ YARN
- 컨테이너 기술 - Docker/K8s
- 클라우드 컴퓨팅 (AWS, GCP, Azure)
- 도움이 되는 기타 지식 (머신러닝 일반, A/B테스트, 통계)
- 데이터 엔지니어 스킬 로드맵 링크
- MLOps혹은 ML Engineer가 다음 스텝이 많이 됨

데이터 웨어하우스 옵션별 장단점
- 데이터 웨어하우스는 기본적으로 클라우드가 대세
- 데이터가 커져도 문제가 없는 확장가능성(Scalable)과 적정한 비용이 중요한 포인트
- 크게 고정비용 옵션과 가변비용 옵션이 존재하며 후자가 좀더 확장가능한 옵션
- AWS의 Redshift, 구글 클라우드의 BigQuery, 스노우플레이크(Snowflake)
- Redshift는 고정비용 옵션이며 BigQuery와 스노우플레이크는 가변비용
- 오픈소스 기반 (Presto, Hive)을 사용하는 경우도 클라우드 버전 존재
- 데이터가 작다면 굳이 빅데이터 기반 데이터베이스를 사용할 필요가 없음
데이터 레이크
- 구조화 데이터 + 비구조화 데이터 (로그파일)
- 보존 기한이 없는 모든 데이터를 원래 형태대로 보존하는 스토리지에 가까움
- 보통은 데이터 웨어하우스보다 몇배는 더 크고 경제적인 스토리지
- 보통은 클라우드 스토리지가 됨
- AWS라면 S3가 대표적인 데이터 레이크라 볼 수 있음
- 데이터 레이크가 있는 환경에서 ETL과 ELT
- 데이터 레이크와 데이터 웨어하우스 바깥에서 안으로 데이터를 가져오는 것 : ETL
- 데이터 레이크와 데이터 웨어하우스 안에 있는 데이터를 처리하는 것 : ELT
ETL -> ELT
- ETL의 수는 회사의 성장에 따라 쉽게 100+개 이상으로 발전
- 중요한 데이터를 다루는 ETL이 실패했을 경우 이를 빨리 고쳐서 다시 실행하는 것이 중요
- 이를 적절하게 스케줄하고 관리하는 것이 중요해지며 그래서 ETL 혹은 프레임웍이 필요해짐
- Airflow가 대표적인 프레임웍
- 데이터 요약을 위한 ETL도 필요해짐 -> ELT 라고 부름
- 앞에서 설명한 ETL은 다양한 데이터 소스에 있는 데이터를 읽어오는 일을 수행.
- 하지만 이를 모두 이해해서 조인해서 사용하는 것은 데이터가 다양해지고 커지면서 거의 불가능해짐.
- 주기적으로 요약데이터를 만들어 사용하는 것이 더 효율적. dbt 사용
- 예) 고객 매출 요약 테이블, 제품 매출 요약 테이블, ...
Airflow (ETL 스케줄러) 소개
- ETL 관리 및 운영 프레임웍의 필요성
- 다수의 ETL이 존재할 경우 이를 스케줄해주고 이들간의 의존관계(dependency)를 정의해주는 기능 필요
- 특정 ETL이 실패할 경우 이에 관한 에러 메세지를 받고 재실행해주는 기능도 중요해짐 (Backfill)
- 가장 많이 사용되는 프레임웍은 Airflow
- Airflow는 오픈소스 프로젝트로 파이썬 3 기반이며 에어비앤비, 우버, 리프트, 쿠팡등에서 사용
- AWS와 구글클라우드와 Azure에서도 지원ㅇ
- Airflow에서는 ETL을 DAG라 부르며 웹 인터페이스를 통한 관리 기능 제공
- 크게 3가지 컴포넌트로 구성됨: 스케줄러, 웹서버, 워커 (Worker)
- Airflow는 오픈소스 프로젝트로 파이썬 3 기반이며 에어비앤비, 우버, 리프트, 쿠팡등에서 사용
ELT
- ETL: 데이터를 데이터 웨어하우스 외부에서 내부로 가져오는 프로세스
- 보통 데이터 엔지니어가 이를 수행함
- ELT: 데이터 웨어하우스 내부 데이터를 조작해서 (보통은 좀더 추상화되고 요약된) 새로운 데이터를 만드는 프로세스
- 이런 프로세스 전용 기술들이 있으며 dbt가 가장 유명: Analytics Engineering
- 보통 데이터 분석가가 이를 수행함
- 이 경우 데이터 레이크를 쓰기도 함
빅데이터 처리 프레임웍
- 분산 환경 기반 (1대 혹은 그 이상의 서버로 구성)
- 분산 파일 시스템과 분산 컴퓨팅 시스템이 필요
- Fault Tolerance
- 소수의 서버가 고장나도 동작해야함
- 확장이 용이해야함
- Scale Out이 되어야함
- 용량을 증대하기 위해서 서버 추가
Hadoop 2.0 and YARN Architecture

데이터 웨어하우스 옵션들
- AWS RedShift
- Snowflake
- Google Cloud BigQuery
- Apache Hive
- Apache Presto
- Apache Iceberg
- Apache Spark
이 옵션들의 공통점 = Iceberg를 제외하고는 모두 SQL을 지원하는 빅데이터 기반 데이터베이스
AWS Redshift
- 2012년에 시작된 AWS 기반의 데이터웨어하우스로 PB 스케일 데이터 분산 처리 가능
- Postgresql과 호환되는 SQL로 처리 가능하게 해줌
- Python UDF (User Defined Function)의 작성을 통해 기능 확장 가능
- 처음에는 고정비용 모델로 시작했으나 이제는 가변비용 모델도 지원 (Redshift Serverless)
- 온디맨드 가격 이외에도 예약 가격 옵션도 지원
- CSV, JSON, Avro, Parquet 등과 같은 다양한 데이터 포맷을 지원
- AWS내의 다른 서비스들과 연동이 쉬움
- S3, DynamoDB, SageMaker 등등
- ML 모델의 실행도 지원 (SageMaker)
- Redshift의 기능 확장을 위해 Redshift Spectrum, AWS Athena등의 서비스와 같이 사용 가능
- S3, DynamoDB, SageMaker 등등
- 배치 데이터 중심이지만 실시간 데이터 처리 지원
- 웹 콘솔 이외에도 API를 통한 관리/제어 가능
Snowflake
- 2014년에 클라우드 기반 데이터웨어하우스로 시작됨 (2020년 상장)
- 지금은 데이터 클라우드라고 부를 수 있을 정도로 발전
- 데이터 판매를 통한 매출을 가능하게 해주는 Data Sharing/Marketplace 제공
- ETL과 다양한 데이터 통합 기능 제공
- SQL 기반으로 빅데이터 저장, 처리, 분석을 가능하게 해줌
- 비구조화된 데이터 처리와 머신러닝 기능 제공
- CSV, JSON, Avro, Parquet 등과 같은 다양한 데이터 포맷을 지원
- S3, GC 클라우드 스토리지, Azure Blog Storage도 지원
- 배치 데이터 중심이지만 실시간 데이터 처리 지원
- 웹 콘솔 이외에도 API를 통한 관리/제어 가능
Google Cloud Bigquery
- 2010년에 시작된 구글 클라우드의 데이터 웨어하우스 서비스
- 구글 클라우드의 대표적인 서비스
- BigQuery SQL이란 SQL로 데이터 처리 가능 (Nested fields, repeated fields 지원)
- 가변 비용과 고정 비용 옵션 지원
- CSV, JSON, Avro, Parquet 등과 같은 다양한 데이터 포맷을 지원
- 구글 클라우드 내의 다른 서비스들과 연동이 쉬움
- 클라우드 스토리지, 데이터플로우, AutoML 등등
- 배치 데이터 중심이지만 실시간 데이터 처리 지원
- 웹 콘솔 이외에도 API를 통한 관리/제어 가능
실리콘밸리 회사들의 데이터 스택 트렌드
데이터 플랫폼의 발전단계
- 초기 단계 : 데이터 웨어하우스 + ETL
- 맨 위에 기입되어있음
- 발전 단계 : 데이터 양 증가
- Spark과 같은 빅데이터 처리시스템 도입
- 데이터 레이크 도입
- 성숙 단계 : 데이터 활용 증대
- 현업단의 데이터 활용이 가속화
- ETL 단이 더 중요해지면서 dbt 등의 analytics engineering 도입
- MLOps 등 머신러닝 관련 효율성 증대 노력 증대
발전 단계 : 데이터 양 증가
- Spark과 같은 빅데이터 처리 시스템 도입
- 데이터 레이크 도입 : 보통 로그 데이터와 같은 대용량 비구조화 데이터 대상
- 데이터 소스 -> 데이터 파이프라인 -> 데이터 웨어하우스
- 데이터 소스 -> 데이터 파이프라인 -> 데이터 레이크
- 데이터 레이크 -> 데이터 파이프라인 -> 데이터 웨어하우스
- 이때 Spark / Hadoop 등이 사용됨
- Hadoop: Hive / Presto 등이 기반
성숙 단계: 현업단의 데이터 활용 가속화
- ELT단이 더 중요해지면서 dbt 등의 analytics engineering 도입
- 데이터 레이크 to 데이터 레이크, 데이터 레이크 to 데이터 웨어하우스, 데이터 웨어하우스 to 데이터 웨어하우
- MLOps 등 머신러닝 개발 운영 관련 효율성 증대 노력 증대
실리콘 밸리 회사 데이터 스택 비교

공부하며 어려웠던 내용
'프로그래머스 데브코스-데이터 엔지니어 > TIL(Today I Learned)' 카테고리의 다른 글
| 05/24 33일차 데이터 웨어하우스 관리와 고급 SQL과 BI 대시보드 (3) (1) | 2023.05.24 |
|---|---|
| 05/23 32일차 데이터 웨어하우스 관리와 고급 SQL과 BI 대시보드 (2) (0) | 2023.05.23 |
| 05/19 30일차 가장 많이 사용되는 AWS 클라우드 (5) (1) | 2023.05.19 |
| 05/18 29일차 가장 많이 사용되는 AWS 클라우드 (4) (0) | 2023.05.18 |
| 05/17 28일차 가장 많이 사용되는 AWS 클라우드 (3) (1) | 2023.05.17 |