DAG
주요 메모 사항
Hello World 예제 MAX님 소스코드 링크
Operators - PythonOperator
2개의 테스크로 구성된 데이터 파이프라인, DAG
- print_hello: PythonOperator로 구성되어 있으며 먼저 실행
- print_goodbye: PythonOperator로 구성되어 있으며 두번째로 실행
Airflow Decorators : 프로그래밍이 단순해짐 MAX님 소스코드 링크
맨 밑에 print_hello() >> print_goodbye() 를 보면 알겠지만, 해당 함수 이름이 테스크 ID가 된다
- Task Decorator를 사용하면 훨씬 더 프로그램이 직관적
- 뒤에 실습에서 두 가지 방식을 혼용해서 사용할 것
중요한 DAG 파라미터 (not task parmeters!)
max_active_runs: # of DAGs instance
max_active_tasks: # of tasks that can run in parallel
catchup: whether to backfill past runs
DAG parameters vs. Task parameters의 차이점 이해가 중요
- 위의 파라미터들은 모두 DAG 파라미터로 DAG 객체를 만들 때 지정해주어야함
Colab Python 코드를 Airflow로 포팅하기 v1 소스코드
이전 포스팅에서 다뤘던 과제들임
- 헤더가 레코드로 추가되는 문제 해결
- Idempotent 하게 job을 만듬 (멱등성!)
- 여러번 실행해도 동일한 결과가 나오게
- 매번 새로 모든 데이터를 읽어오는 job라고 가정하고 구현
v1 소스코드 개선하기 -> v2 소스코드
- params를 통해 변수 넘기기
- execution_date 얻어내기
- “delete from” vs. “truncate”
- DELETE FROM raw_data.name_gender; -- WHERE 사용 가능
- TRUNCATE raw_data.name_gender;
v2 소스코드 개선하기 -> v3 소스코드
- Xcom 객채를 사용해서 세개의 task로 나누기
- Redshift의 스키마와 테이블 이름을 params로 넘기기
- v3 소스코드의 Line 72
Xcom이란?
- 태스크(Operator)들간에 데이터를 주고 받기 위한 방식
- 보통 한 Operator의 리턴값을 다른 Operator에서 읽어가는 형태가 됨
- 이 값들은 Airflow 메타 데이터 DB에 저장이 되기에 큰 데이터를 주고받는데는 사용불가
- 보통 큰 데이터는 S3등에 로드하고 그 위치를 넘기는 것이 일반적
- 태스크 하나로 구성이 된 경우
- 3개의 테스크로 나눈 경우

Connections and Variables
우리가 사용하던 get_redshift 함수에 사용했던 host라던지, 개인 id pw등이 노출되는 것을 Connections 으로 설정
S3 링크를 Variables를 사용해 암호화 하는 등
- Connections
- This is used to store some connection related info such as hostname, port number, and access credential
- Postgres connection or Redshift connection info can be stored here
- Variables
- Used to store API keys or some configuration info
- Use “access” or “secret” in the name if you want its value to be encrypted
- We will practice this
Web UI로 설정 가능


Variable를 이용해 CSV parameter 넘기기

v3 소스코드 개선하기 -> v4 소스코드
- Redshift Connection 사용하기
- schema 변경 잊지 말기!
Redshift Connection 설정 (Data Warehouse)
Web UI에서 설정 가능

v4 소스코드 개선하기 -> v5 소스코드
from airflow.decorators import task
- task decorator를 사용
- 이 경우 xcom을 사용할 필요가 없음
- 기본적으로 PythonOperator 대신에 airflow.decorators.task를 사용
실습 환경을 준비했다면 링크 를 clone 해서 실습
Yahoo Finance API DAG 작성
Yahoo Finance API를 호출해서 애플 주식을 읽어오는 Full Refresh 기반의 DAG
구현 DAG의 세부 사항 - Full Refresh로 구현
1. Yahoo Finance API를 호출하여 애플 주식 정보 수집 (지난 30일)
2. Redshift 상의 테이블로 1에서 받은 레코드들을 적재
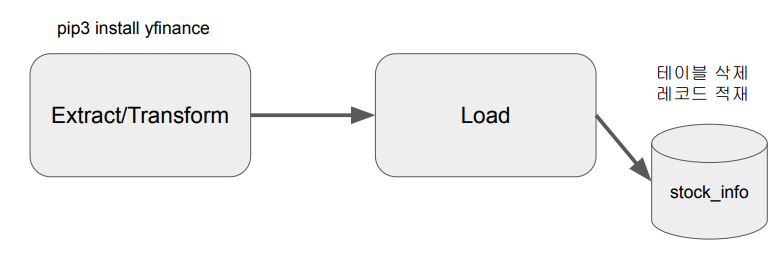
Extract/Transform: Yahoo Finance API 호출 # git sourcecode Line 20
Yahoo Finance API를 호출하여 애플 주식 정보 수집하고 파싱
-> 기본으로 지난 한달의 주식 가격을 리턴해줌
Load: Redshift의 테이블을 업데이트
- Full Refresh로 구현 - 매번 테이블을 새로 만드는 형태로 구성
- 트랜잭션 형태로 구성 (NameGender DAG와 동일)
구현 DAG의 세부 사항 - Incremental Update로 구현 git 링크
1. Yahoo Finance API를 호출하여 애플 주식 정보 수집 (지난 30일)
2. Redshift 상의 테이블로 1에서 받은 레코드들을 적재하고 중복 제거 - 매일 하루치의 데이터씩 늘어남

Extract/Transform: Yahoo Finance API 호출 -> 동일
Load: Redshift의 테이블을 업데이트
- Incremental Update로 구현
- 임시 테이블 생성하면서 현재 테이블의 레코드를 복사 (CREATE TEMP TABLE … AS SELECT)
- 임시 테이블로 Yahoo Finance API로 읽어온 레코드를 적재
- 원본 테이블을 삭제하고 새로 생성
- 원본 테이블에 임시 테이블의 내용을 복사 (이 때 SELECT DISTINCT *를 사용하여 중복 제거)
- 트랜잭션 형태로 구성 (NameGender DAG와 동일)
Q&A
PostgresHook의 autocommit 파라미터
- Default 값은 False로 주어짐
- False, 이 경우 BEGIN은 아무런 영향이 없음 (no-operation)
DAG에서 task를 어느 정도로 분리하는 것이 좋을까?
아마도 엔지니어로써의 경험이 필요할
- task를 많이 만들면 전체 DAG이 실행되는데 오래 걸리고 스케줄러에 부하가 감
- task를 너무 적게 만들면 모듈화가 안되고 실패시 재실행을 시간이 오래 걸림
- 오래 걸리는 DAG이라는 실패시 재실행이 쉽게 다수의 task로 나누는 것이 좋음
Airflow의 Variable 관리 vs. 코드 관리
장점: 코드 푸시의 필요성이 없음
단점: 관리나 테스트가 안되어서 사고로 이어질 가능성이 있음
숙제
다음 포스팅에서 다룸
airflow.cfg
1. DAGs 폴더는 어디에 지정되는가?
2. DAGs 폴더에 새로운 Dag를 만들면 언제 실제로 Airflow 시스템에서 이를 알게 되나? 이 스캔 주기를 결정해주는 키의 이름이 무엇인가?
3. 이 파일에서 Airflow를 API 형태로 외부에서 조작하고 싶다면 어느 섹션을 변경해야하는가?
4. Variable에서 변수의 값이 encrypted가 되려면 변수의 이름에 어떤 단어들이 들어가야 하는데 이 단어들은 무엇일까?
5. 이 환경 설정 파일이 수정되었다면 이를 실제로 반영하기 위해서 해야 하는 일은?
6. Metadata DB의 내용을 암호화하는데 사용되는 키는 무엇인가?
세계 나라 정보 API 사용 DAG 작성
- https://restcountries.com/ 에 가면 세부 사항을 찾을 수 있음 - API key 필요 X
- https://restcountries.com/v3/all를 호출하여 나라별로 다양한 정보를 얻을 수 있음
Full Refresh로 구현해서 매번 국가 정보를 읽어오게 할 것!
API 결과에서 아래 3개의 정보를 추출하여 Redshift에 각자 스키마 밑에 테이블 생성
- country -> [“name”][“official”]
- population -> [“population”]
- area -> [“area”]
단 이 DAG는 UTC로 매주 토요일 오전 6시 30분에 실행되게 만들어볼 것!
숙제는 개인 github에 repo를 만든 후 제출할 것!
공부하며 어려웠던 내용
실습 환경을 준비해야한다. -> 라즈베리파이로 불가능 할 것 같아서 개인 데스크탑 WSL2를 사용해 Ubuntu에서 실습
'프로그래머스 데브코스-데이터 엔지니어 > TIL(Today I Learned)' 카테고리의 다른 글
| 06/09 45일차 데이터 파이프라인과 Airflow (5) (0) | 2023.06.09 |
|---|---|
| 06/08 44일차 데이터 파이프라인과 Airflow (4) (0) | 2023.06.08 |
| 06/06 42일차 데이터 파이프라인과 Airflow (2) (0) | 2023.06.06 |
| 06/05 41일차 데이터 파이프라인과 Airflow (1) (0) | 2023.06.05 |
| 05/29 ~ 06/02, 36~40일차 2번째 프로젝트 (0) | 2023.06.03 |