Spark 구조, Spark DataFrame
주요 메모 사항
Spark 데이터 처리
Spark 데이터 시스템 아키텍처

데이터 병렬처리가 가능하려면? -> 데이터가 먼저 분산되어야함
하둡 맵의 데이터 처리 단위는 디스크에 있는 데이터 블록 (128MB)
ㄴ hdfs-site.xml에 있는 dfs.block.size 프로퍼티가 결정
Spark에서는 이를 파티션 (Partition)이라 부름. 파티션의 기본크기도 128MB
ㄴ spark.sql.files.maxPartitionBytes: 파티션의 기본크기 변경, HDFS등에 있는 파일을 읽어올 때만 적용됨
다음으로 나눠진 데이터를 각각 따로 동시 처리
ㄴ 맵리듀스에서 N개의 데이터 블록으로 구성된 파일 처리시 N개의 Map 태스크가 실행
ㄴ Spark에서는 파티션 단위로 메모리로 로드되어 Executor가 배정됨
처리 데이터를 나누기 -> 파티션 -> 병렬처리
source의 lang에 따라서 파티셔닝 하는 방법이 필요
cpu = 2, excutor = 2, dataframe = 4라면?
ㄴ executor에 cpu은 1개씩 할당, dataframe은 2개씩 할당 -> 동시에 2개의 df를 처리

Spark 데이터 처리 흐름
데이터프레임은 작은 파티션들로 구성됨
ㄴ 데이터프레임은 한번 만들어지면 수정 불가 (Immutable)
입력 데이터프레임을 원하는 결과 도출까지 다른 데이터 프레임으로 계속 변환
ㄴ sort, group by, filter, map, join, …

셔플링: 파티션간에 데이터 이동이 필요한 경우 발생
셔플링이 발생하는 경우는?
명시적 파티션을 새롭게 하는 경우 (예: 파티션 수를 줄이기)
시스템에 의해 이뤄지는 셔플링
ㄴ 예를 들면 그룹핑 등의 aggregation이나 sorting
셔플링이 발생할 때 네트웍을 타고 데이터가 이동하게 됨

몇 개의 파티션이 결과로 만들어질까?
ㄴ spark.sql.shuffle.partitions이 결정
ㄴ 기본값은 200이며 이는 최대 파티션 수
ㄴ 오퍼레이션에 따라 파티션 수가 결정됨
ㄴ random, hashing partition, range partition 등등
ㄴ sorting의 경우 range partition을 사용함
ㄴ 모든 값을 확인하는게 아니라 sampling
ㄴ> 또한 이때 Data Skew 발생 가능!
셔플링: hashing partition (Group By)
Aggregation 오퍼레이션

Data Skewness
Data partitioning은 데이터 처리에 병렬성을 주지만 단점도 존재
ㄴ 이는 데이터가 균등하게 분포하지 않는 경우 -> 주로 데이터 셔플링 후에 발생
ㄴ 셔플링을 최소화하는 것이 중요하고 파티션 최적화를 하는 것이 중요.

Spark 데이터 구조
RDD, DataFrame, Dataset
Spark 데이터 구조
RDD, DataFrame, Dataset (Immutable Distributed Data)
ㄴ 2016년에 DataFrame과 Dataset은 하나의 API로 통합됨
ㄴ 모두 파티션으로 나뉘어 Spark에서 처리됨

Spark 데이터 구조
RDD (Resilient Distributed Dataset)
ㄴ 로우레벨 데이터로 클러스터내의 서버에 분산된 데이터를 지칭
ㄴ 레코드별로 존재하지만 스키마가 존재하지 않음
ㄴ 구조화된 데이터나 비구조화된 데이터 모두 지원
DataFrame과 Dataset
ㄴ RDD위에 만들어지는 RDD와는 달리 필드 정보를 갖고 있음 (테이블)
ㄴ Dataset은 타입 정보가 존재하며 컴파일 언어에서 사용가능
ㄴ Scala/Java에서 사용가능
ㄴ PySpark에서는 DataFrame을 사용
Spark 데이터 구조

Spark SQL Engine 컴포넌트 동작
1. Code Analysis
2. Logical Optimization (Catalyst Optimizer)
3. Physical Planning
4. Code Generation (Project Tungsten)
Spark 데이터 구조 - RDD
변경이 불가능한 분산 저장된 데이터
ㄴ RDD는 다수의 파티션으로 구성
ㄴ 로우레벨의 함수형 변환 지원 (map, filter, flatMap 등등)
일반 파이썬 데이터는 parallelize 함수로 RDD로 변환
ㄴ 반대는 collect로 파이썬 데이터로 변환가능
Spark 데이터 구조 - 데이터 프레임
변경이 불가한 분산 저장된 데이터
RDD와는 다르게 관계형 데이터베이스 테이블처럼 컬럼으로 나눠 저장
ㄴ 판다스의 데이터 프레임 혹은 관계형 데이터베이스의 테이블과 거의 흡사
ㄴ 다양한 데이터소스 지원: HDFS, Hive, 외부 데이터베이스, RDD 등등
스칼라, 자바, 파이썬과 같은 언어에서 지원
-> 실습은 DataFrame로 사용할 예정
프로그램 구조
Spark Session 생성 Reference Docs
Spark 프로그램의 시작은 SparkSession을 만드는 것
ㄴ 프로그램마다 하나를 만들어 Spark Cluster와 통신: Singleton 객체
ㄴ Spark 2.0에서 처음 소개됨
Spark Session을 통해 Spark이 제공해주는 다양한 기능을 사용
ㄴ DataFrame, SQL, Streaming, ML API 모두 이 객체로 통신
ㄴ config 메소드를 이용해 다양한 환경설정 가능
ㄴ 단 RDD와 관련된 작업을 할때는 SparkSession 밑의 sparkContext 객체를 사용
PySpark 예제
디자인 패턴 - 싱글턴
Driver == .py
Spark Session = spark 객체
pyspark.sql로 연결된 Spark Cluster의 Cluster Manager과 통신

Spark Session 환경 변수
Spark Session을 만들 때 다양한 환경 설정이 가능
몇 가지 예
executor별 메모리: spark.executor.memory (기본값: 1g)
executor별 CPU수: spark.executor.cores (YARN에서는 기본값 1)
driver 메모리: spark.driver.memory (기본값: 1g)
Shuffle후 Partition의 수: spark.sql.shuffle.partitions (기본값: 최대 200)
가능한 모든 환경변수 옵션은 여기에서 찾을 수 있음
ㄴ 사용하는 Resource Manager에 따라 환경변수가 많이 달라짐
Spark Session 환경 설정 방법 4가지
1. 환경변수
2. $SPARK_HOME/conf/spark_defaults.conf
3. spark-submit 명령의 커맨드라인 파라미터
ㄴ 나중에 따로 설명
4. SparkSession 만들때 지정
ㄴ SparkConf
1, 2 번은 보통 Spark Cluster 어드민이 관리
충돌시 우선순위는 아래일수록 높음
Spark 세션 환경 설정
1. SparkSession 생성시 일일히 지정

이 시점의 Spark Configuration은 앞서 언급한 환경변수와 spark_defaults.conf와 spark-submit로 들어온 환경설정이 우선순위를 고려한 상태로 정리된 상태, Overriding 하는 형태
2. SparkConf 객체에 환경 설정하고 SparkSession에 지정
set() 으로 환경변수 Key, Value 형태로 지정을 할 수도 있음

전체적인 플로우
1. Spark 세션(SparkSession)을 만들기
2. 입력 데이터 로딩
3. 데이터 조작 작업 (판다스와 아주 흡사)
ㄴ DataFrame API나 Spark SQL을 사용
ㄴ 원하는 결과가 나올때까지 새로운 DataFrame을 생성
4. 최종 결과 저장

Spark Session이 지원하는 데이터 소스
spark.read(DataFrameReader)를 사용하여 데이터프레임으로 로드
DataFrame.write(DataFrameWriter)을 사용하여 데이터프레임을 저장
많이 사용되는 데이터 소스들
- HDFS 파일
ㄴ CSV, JSON, Parquet, ORC, Text, Avro
ㄴ Parquet/ORC/Avro에 대해서는 나중에 더 자세히 설명
ㄴ Hive 테이블
- JDBC 관계형 데이터베이스
- 클라우드 기반 데이터 시스템
- 스트리밍 시스템
개발/실습 환경 소개
Spark 개발 환경 옵션
- Colab에서 진행 예정
- 다만, 기용님이 Local Standalone로 시용하는 것도 보여주심
Local Standalone Spark

Spark Cluster Manager로 local[n] 지정
ㄴ master를 local[n]으로 지정
ㄴ master는 클러스터 매니저를 지정하는데 사용
주로 개발이나 간단한 테스트 용도
하나의 JVM에서 모든 프로세스를 실행
ㄴ 하나의 Driver와 하나의 Executor가 실행됨
ㄴ 1+ 쓰레드가 Executor안에서 실행됨
Executor안에 생성되는 쓰레드 수
ㄴ local:하나의 쓰레드만 생성
ㄴ local[*]: 컴퓨터 CPU 수만큼 쓰레드를
구글 Colab에서 Spark 사용
PySpark + Py4J를 설치
ㄴ 구글 Colab 가상서버 위에 로컬 모드 Spark을 실행
ㄴ 개발 목적으로는 충분하지만 큰 데이터의 처리는 불가
ㄴ Spark Web UI는 기본적으로는 접근 불가
ㄴ ngrok을 통해 억지로 열 수는 있음, 추천 X
Py4J
ㄴ 파이썬에서 JVM내에 있는 자바 객체를 사용가능하게 해줌
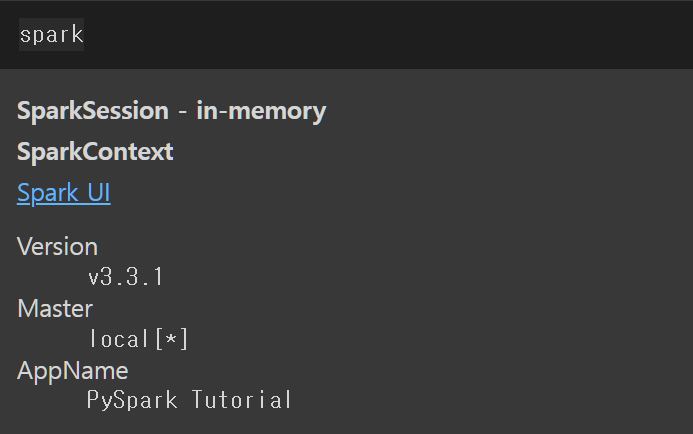
Colab - PySpark 설치 및 테스트
!pip install pyspark==3.3.1 py4j==0.10.9.5
from pyspark.sql import SparkSession
spark = SparkSession.builder\
.master("local[*]")\
.appName('PySpark Tutorial')\
.getOrCreate()


Pandas DataFrame 실습
실습 1. 워밍업 - 헤더가 없는 CSV 파일 처리하기
- 데이터에 스키마 지정하기
- SparkConf 사용해보기
- measure_type값이 TMIN인 레코드 대상으로 stationId별 최소 온도 찾기
ㄴ 판다스와 비교
pyspark.sql.types
- IntegerType, LongType, FloatType, StringType, BooleanType
- TimestampType, DateType
- ArrayType, StructType, StructField, MapType
DataFrame의 컬럼을 지칭하는 방식
다음과 같은 csv 파일로 실습 진행

컬럼 지정

measure_type 이 TMIN인 rows만 pd_minTemps로 선언

TMIN 타입의 stationID를 그룹화해 가장 낮은 온도만 출력

Spark DataFrame 실습
먼저 SparkConf 객체를 만들어 master 설정을 해줌 (master 설정은 클러스터 매니저의 주소 또는 URL임)
df에 long form으로 read했는데 주석과 같이 short form으로도 가능함
그리고 Spark가 어떻게 스키마를 구성하는지 print

DataFrame의 이름을 지정해줌, 하지만 type들이 아직 모두 string임

.option()으로 inferSchema 파라미터를 true로 주면 Spark가 몇개의 데이터를 샘플링해서 예상 Type을 지정해 줌 (default는 False임)

컬럼이름과 타입을 명시적으로 지정
StructType으로 미리 선언한 객체를 spark.read.schema() 에서 파라미터 값으로 사용할 수 있음

필터링 적용하는 방법들, 이 외에도 다양함



select 메소드도 존재


minTemps의 stationID, 최소값을 가진 minTempsByStation을 python으로 값을 넘겨받아 보자

collect 메소드로 넘겨받는게 가능, 그렇다면 return된 객체의 type은?

list로 반환됨


이번엔 sql 메소드로 collect 진행

Row로 출력되는 라인의 type은 다음과 같음

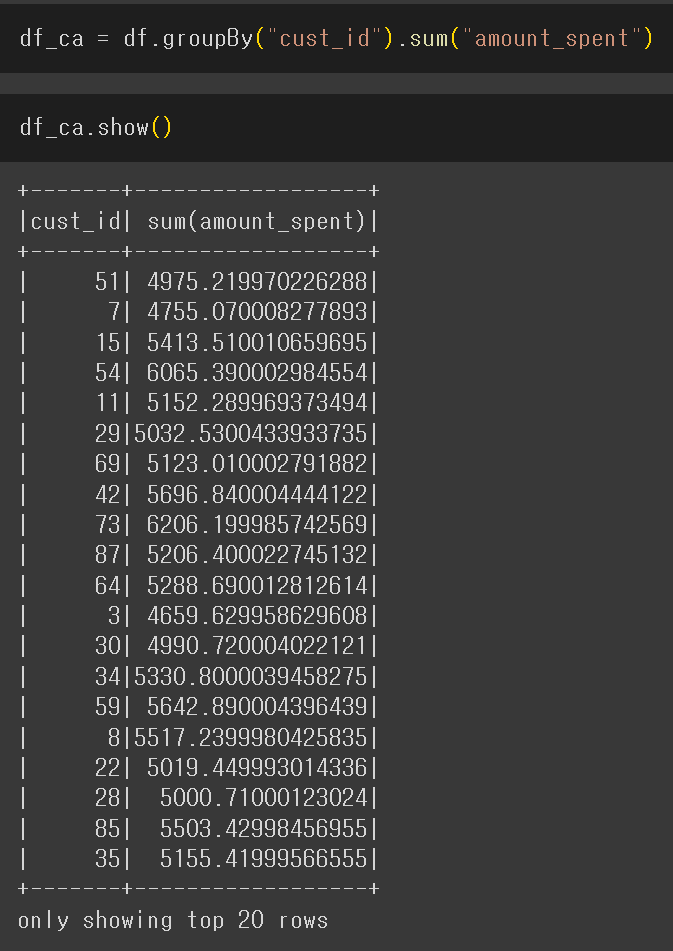
실습 2. 워밍업 2 - 헤더 없는 CSV 파일처리하기
csv 파일 구조

column 이름과 타입을 지정

cust_id 별로 amount_spent의 총합을 구함
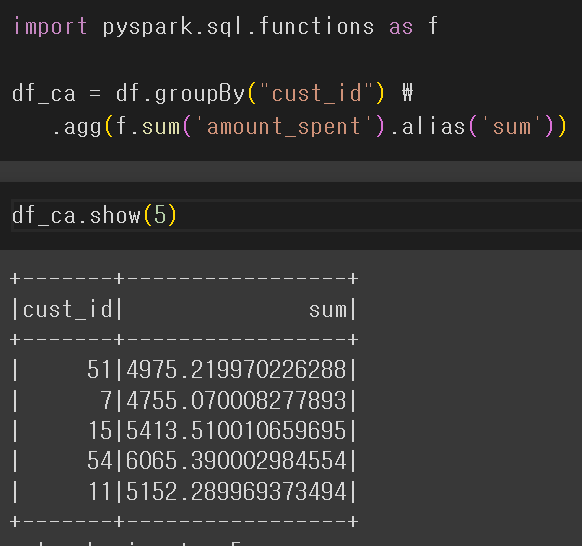
컬럼 이름을 Rename, 이 외에도 다양한 방법 존재

이번엔 sum 말고 max나 avg를 구해봄

임시로 View 테이블을 Ram 메모리에 저장
위에서 사용한 메소드들을 sql로 처리

Spark은 기본으로 in-memory 카탈로그를 사용.
스토리지 기반의 카탈로그를 쓰고 싶다면 SparkSession 설정할 때 enableHiveSupport()를 호출 (Hive metastore를 카탈로그로 사용하며 Hive UDF와 Hive 파일포맷 사용 가능)

실습 3. 텍스트를 파싱해서 구조화된 데이터로 변환하기
ㄴ Regex를 이용해서 아래와 같이 변환해보는 것이 목표
예시

다음 txt 파일로 실습

실제 파일을 불러올때 .text() 메소드로 선언

dataframe이 지원해주는 withColumn 메소드를 사용해서 regexp_extract (UDF)를 사용
regexp_extract를 사용할 때, 미리 정의한 정규식을 참조하는데 index는 1번부터 시작

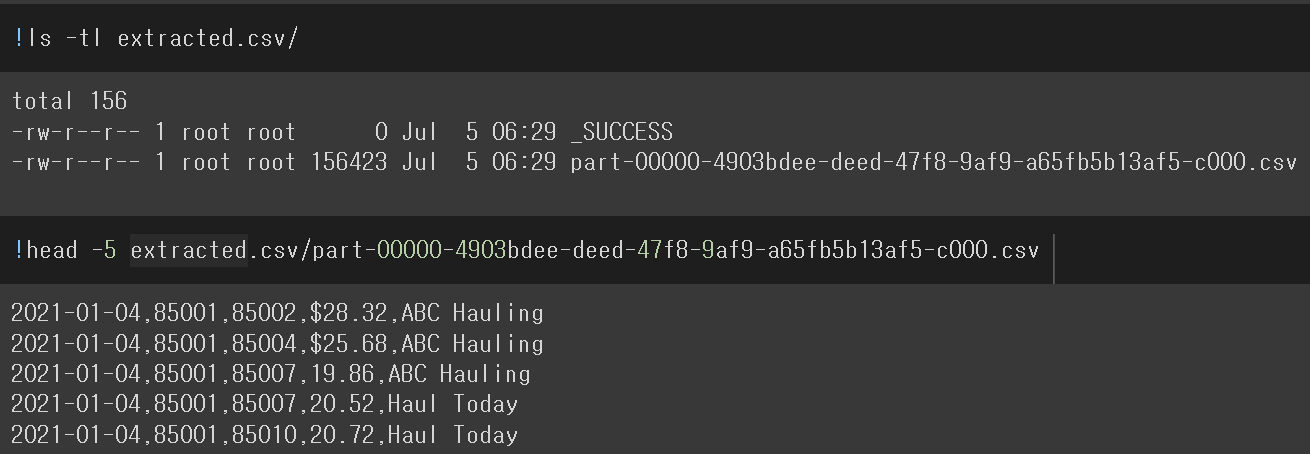
이제 필요없어진 text 컬럼을 drop 해주고 .write.csv()로 저장
근데 디렉토리로 저장된 것을 볼 수 있음, 내부적으로 Data Block 단위로 저장이 됨 -> 그래서 폴더로 저장이 되고 폴더 내부에 여러개의 파일로 저장

다만, 실습을 진행한 text 파일의 크기가 작다보니 1개로만 저장되었음
Json으로 저장도 가능, 마찬가지로 폴더 구조로 저장

실습 4. Stackoverflow 서베이 기반 인기 언어 찾기
stackoverflow CSV파일에서 다음 두 필드는 ;를 구분자로 프로그래밍 언어를 구분
ㄴ LanguageHaveWorkedWith, LanguageWantToWorkWith
-> 이를 별개 레코드로 분리하여 가장 많이 사용되는 언어 top 50와 가장 많이 쓰고 싶은 언어 top 50를 계산해보기

사용할 컬럼만 select 해서 df선언

F.col(), 원하는 컬럼의 rows 선택 -> F.trim(f.col()), 양쪽 공백 삭제
ㄴ> F.split(F.trim(F.col()), ':'), 콜론을 구분자로 사용해 split
ㄴ> 해당 Rows를 language_have 컬럼에 저장
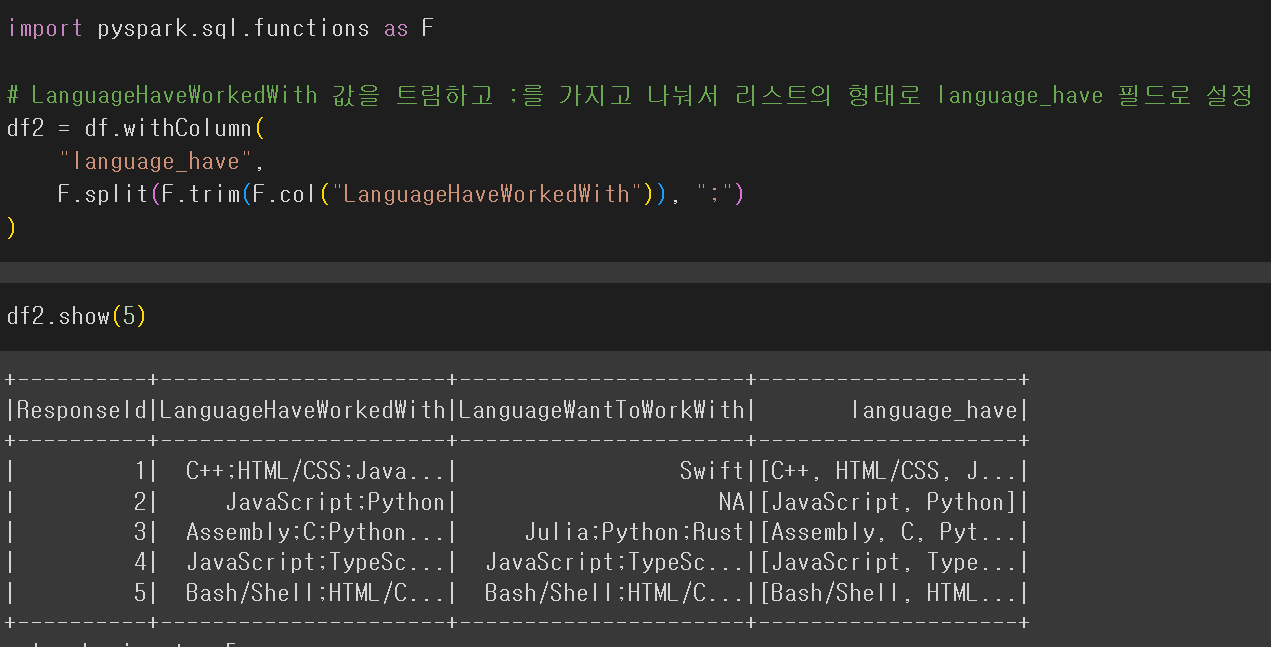
위와 같은 방법으로 LanguageWant 도 추가해줌

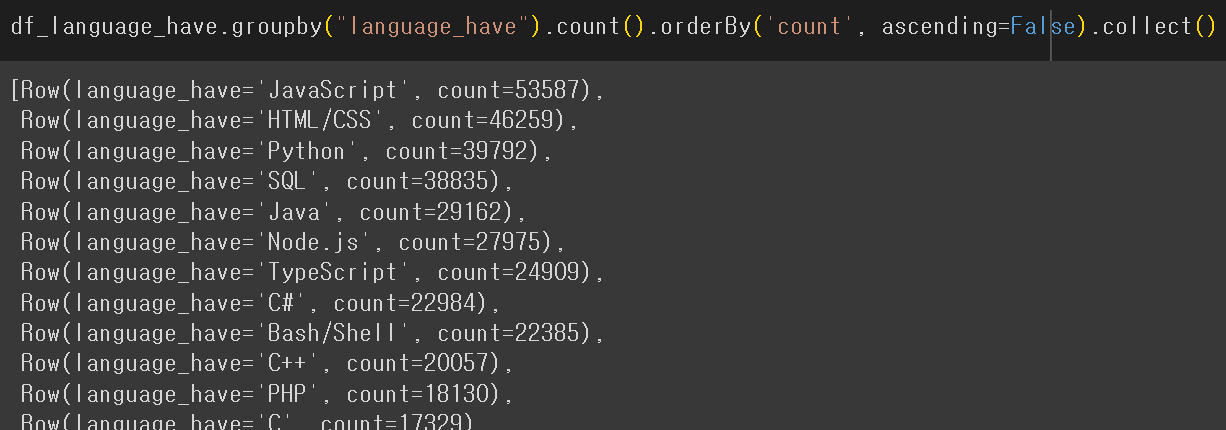
가장 많이 사용되는 언어
F.explode()는 array 타입으로 존재하는 값을 언패킹해 rows로 반환해줌

groupby로 count -> Sort가 필요해 보임

Sorting 두 가지 방법:
ㄴ sort & orderBy
ㄴ ascending & descending
sort, desc

orderBy, desc
mode 메소드로 overwrite 하게 저장 가능

가장 많이 배우고싶은 언어 - 생략, 같은 맥락임
실습 5. Redshift 연결해보기
- MAU (Monthly Active User) 계산해보기
- 두 개의 테이블을 Redshift에서 Spark으로 로드 -> JDBC 연결 실습
- DataFrame과 SparkSQL을 사용해서 조인
- DataFrame JOIN
ㄴ left_DF.join(right_DF, join condition, join type)
ㄴ join type: “inner”, “left”, “right”, “outer”, “semi”, “anti”
Redshift에 JDBC 드라이버를 통해 연결할 예정이므로 wget 해준다

Redshift와 연결해서 테이블을 Dataframe로 로딩

sessionid 를 join key로 inner join을 진행
sessionid 가 2개가 출력됨 -> 문제가 되는 것을 제거해야함

session_id가 중복으로 들어가지 않게 select를 사용해서 명시적으로 수

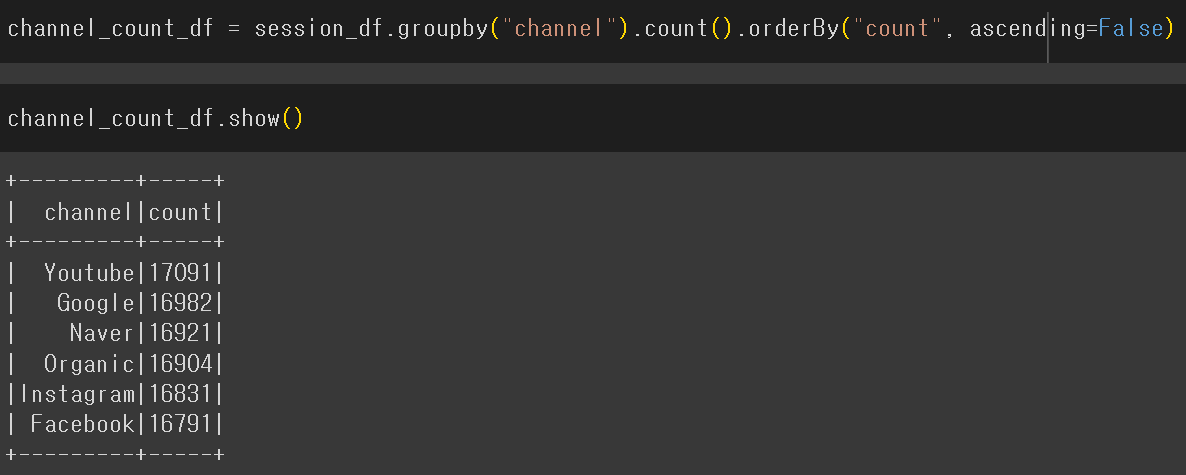
channel의 count를 desc으로 새로운 df를 생성
mau 계산
1. withColumn으로 month 컬럼을 yyyy-MM 형태로 변환
2. month 컬럼으로 그룹화
3. countDistinct로 중복값 없이 userid를 count 해주고 mau로 이름 지정
4. 해당 값을 agg 메소드로 집계
5. month 컬럼을 asc으로 sort

mau 계산을 Spark SQL로 처리한다면?
먼저 사용 df 초기화

mau 계산
spark.sql() 메소드가 훨씬 간단하기는 하다

공부하며 어려웠던 내용
pyspark를 사용하는 것 자체는 어렵지 않으나, spark에 대한 개념이 아직 자리잡히지 않은 것 같
'프로그래머스 데브코스-데이터 엔지니어 > TIL(Today I Learned)' 카테고리의 다른 글
| 07/06 64일차 Spark의 내부동작 | ML | 클라우드 (0) | 2023.07.06 |
|---|---|
| 07/05 63일차 Spark SQL (0) | 2023.07.05 |
| 07/03 61일차 빅데이터 처리 시스템, Hadoop, Spark (0) | 2023.07.03 |
| 06/26 ~ 06/30, 56~60일차 3번째 프로젝트 (0) | 2023.06.27 |
| 06/23 55일차 DBT와 데이터 카탈로그 (2) | 2023.06.23 |