Kafka
주요 메모 사항
Kafka 소개
Kafka란 무엇인가?
- 실시간 데이터를 처리하기 위해 설계된 오픈소스 분산 스트리밍 플랫폼
ㄴ 데이터 재생이 가능한 분산 커밋 로그 (Distributed Commit Log)
- Scalability와 Fault Tolerance를 제공하는 Publish-Subscription 메시징 시스템
ㄴ Producer-Consumer
- High Throughput과 Low Latency 실시간 데이터 처리에 맞게 구현됨
- 분산 아키텍처를 따르기 때문에 Scale Out이란 형태로 스케일 가능
ㄴ 서버 추가를 통해 Scalability 달성 (서버 = Broker)
- 정해진 보유기한 (retention period) 동안 메시지를 저장
기존 메시징 시스템 및 데이터베이스와의 비교
기존 메시징 시스템과 달리, 카프카는 메시지를 보유 기간 동안 저장
ㄴ 소비자가 오프라인 상태일 때에도 내구성과 내결함성을 보장
ㄴ 기본 보유 기간은 일주일
Kafka는 메시지 생산과 소비를 분리
ㄴ 생산자와 소비자가 각자의 속도에 맞춰 독립적으로 작업이 가능하도록 함
ㄴ 시스템 안정성을 높일 수 있음
Kafka는 높은 처리량과 저지연 데이터 스트리밍을 제공
ㄴ Scale-Out 아키텍처
한 파티션 내에서는 메세지 순서를 보장해줌
ㄴ 다수의 파티션에 걸쳐서는 “Eventually Consistent”
ㄴ 토픽을 생성할 때 지정 가능 (Eventual Consistency vs. Strong Consistency)
사내 내부 데이터 버스로 사용되기 시작
ㄴ 워낙 데이터 처리량이 크고 다수 소비자를 지원하기에 가능
Eventual Consistency란?
100대 서버로 구성된 분산 시스템에 레코드를 하나 쓴다면 그 레코드를 바로 읽을 수 있을까?
ㄴ 보통 하나의 데이터 블록은 여러 서버에 나눠 저장됨 (Replication Factor)
ㄴ 그래서 데이터를 새로 쓰거나 수정하면 이게 전파되는데 시간이 걸림
ㄴ 보통 읽기는 다수의 데이터 카피 중에 하나를 대상으로 일어나기 때문에 앞서 전파 시간에 따라 데이터가 있을 수도 있고 없을 수도 있음
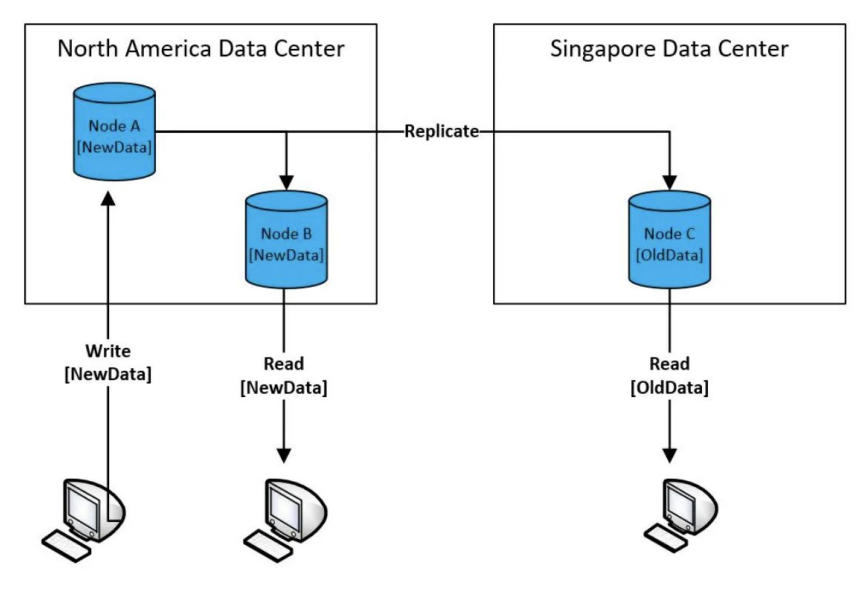
Strong Consistency vs. Eventual Consistency
보통 데이터를 쓸때 복제가 완료될 때까지 기다리는 구조라면 Strong Consistency
그게 아니라 바로 리턴한다면 Eventual Consistency
Kafka의 주요 기능 및 이점
스트림 처리
ㄴ Kafka는 실시간 스트림 처리를 목표로 만들어진 서비스
ㄴ ksqlDB를 통해 SQL로도 실시간 이벤트 데이터 처리 가능
High Throughput (높은 처리량)
ㄴ Kafka는 초당 수백만 개의 메시지 처리 가능
Fault Tolerance (내결함성)
ㄴ Kafka는 데이터 복제 및 분산 커밋 로그 기능을 제공하여 장애 대응이 용이
Scalability (확장성)
ㄴ Kafka의 분산 아키텍처는 클러스터에 브로커를 추가하여 쉽게 수평 확장 가능
풍부한 생태계의 존재
ㄴ Kafka는 커넥터와 통합 도구로 구성된 풍부한 에코시스템을 갖추고 있어 다른 데이터 시스템 및 프레임워크와 쉽게 연동 가능
ㄴ Kafka Connect, Kafka Schema Registry
Kafka 아키텍처
데이터 이벤트 스트림
데이터 이벤트 스트림을 Topic이라고 부름
ㄴ Producer는 Topic을 만들고 Consumer는 Topic에서 데이터를 읽어들이는 구조
ㄴ 다수의 Consumer가 같은 Topic을 기반으로 읽어들이는 것이 가능

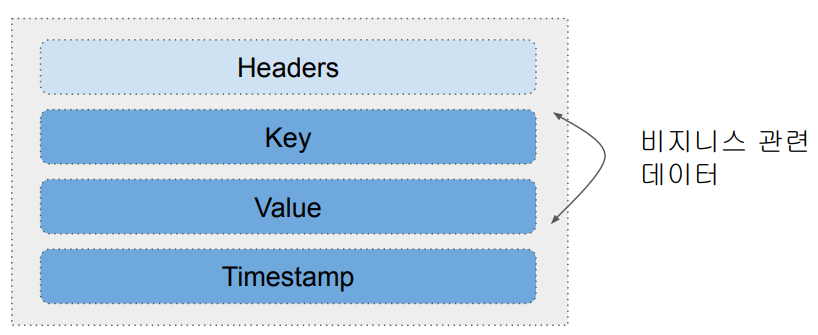
Message (Event) 구조: Key, Value, Timestamp
- 최대 1MB
- Timestamp는 보통 데이터가 Topic에 추가된 시점
- Key 자체도 복잡한 구조를 가질 수 있음
ㄴ Key가 나중에 Topic 데이터를 나눠서 저장할 때 사용됨 (Partitioning)
- Header는 선택적 구성요소로 경량 메타 데이터 정보 (key-value pairs)
Kafka 아키텍처 - Topic과 Partition
- 하나의 Topic은 확장성을 위해 다수의 Partition으로 나뉘어 저장됨
- 메세지가 어느 Partition에 속하는지 결정하는 방식에 키의 유무에 따라 달라짐
ㄴ 키가 있다면 Hashing 값을 Partition의 수로 나눈 나머지로 결정
ㄴ 키가 없다면 라운드 로빈으로 결정 (비추)

Kafka 아키텍처 - Topic과 Partition과 복제본
- 하나의 Partition은 Fail-over를 위해 Replication Partition을 가짐
- 각 Partition별로 Leader와 Follower가 존재
ㄴ 쓰기는 Leader를 통해 이뤄지고 읽기는 Leader/Follower들을 통해 이뤄짐
ㄴ Partition별로 Consistency Level을 설정 가능 (in-sync replica - “ack”)
-> Partition별로 누가 Leader이고 Follower인지 관리가 중요해짐

Kafka 아키텍처 - Topic 파라미터들 링크
이름: “MyTopic”
Partition의 수: 3
복제본의 수: 3
Consistency Level (“acks”): “all”
데이터 보존 기한: 기본 일주일
메세지 압축 방식
ㄴ> Topic 예시

Kafka 아키텍처 - Broker: 실제 데이터를 저장하는 서버
Kafka 클러스터는 기본적으로 다수의 Broker로 구성됨
ㄴ 여기에 원활한 관리와 부가 기능을 위한 다른 서비스들이 추가됨 (Zookeeper가 대표적)
ㄴ 한 클러스터는 최대 20만개까지 partition을 관리 가능
ㄴ Broker들이 실제로 Producer/Consumer들과 통신 수행
앞서 이야기한 Topic의 Partition들을 실제로 관리해주는 것이 Broker
ㄴ 한 Broker는 최대 4000개의 partition을 처리 가능
Broker는 물리서버 혹은 VM 위에서 동작
ㄴ 해당 서버의 디스크에 Partition 데이터들을 기록함
Broker의 수를 늘림으로써 클러스터 용량을 늘림 (Scale Out)
앞서 20만개, 4천개 제약은 Zookeeper를 사용하는 경우임
ㄴ 이 문제 해결을 위해서 Zookeeper를 대체하는 모드도 존재 (KRaft)
Kafka 아키텍처 - Broker와 Partition
- Kafka Broker를 Kafka Server 혹은 Kafka Node라고 부르기도 함
- 누가 어디에 Broker, Topic에 대한 정보를 관리하는가?

Kafka 아키텍처 - 메타 정보 관리를 어떻게 할 것인가?
- Broker 리스트 관리 (Broker Membership)
ㄴ 누가 Controller인가? (Controller Election)
- Topic 리스트 관리 (Topic Configuration)
ㄴ Topic을 구성하는 Partition 관리
ㄴ Partition별 Replica 관리
ㄴ Partition들을 관리해주는 역할을 하는 것이 Controller (Broker중의 하나가 이 역할을 수행)
- Topic별 ACL (Access Control Lists) 관리
- Quota 관리
Kafka 아키텍처: Zookeeper와 Controller
Controller는 Broker이면서 Partition 관리
현재로는 두 가지 모드가 존재
Zookeeper 모드
ㄴ 3, 5, 7대의 서버를 Zookeeper Ensemble을 구성하기 위해 사용
ㄴ Controller가 Zookeeper를 통해 메타데이터 관리와 리더 선출 담당
ㄴ 하나의 Controller가 존재
KRaft 모드
ㄴ Zookeeper를 완전히 배제 Controller가 역할을 대신 수행
ㄴ 다수의 Controller들이 Zookeeper 역할을 대신 수행
ㄴ Controller들은 보통 Broker들이기도 함
Zookeeper란?
분산 시스템에서 널리 사용되는 Distributed Coordination Service
ㄴ 동기화, 구성 관리, 리더 선출 등 분산 시스템의 관리하고 조율을 위한 중앙 집중 서비스 제공
다양한 문제 존재
ㄴ 지원하는 데이터 크기가 작고 동기모드로 동작하기에 처리 속도가 느림
ㄴ 즉 어느 스케일 이상으로 확장성이 떨어짐
ㄴ 환경설정도 복잡함
ㄴ 그러다보니 Zookeeper를 사용하던 서비스들이 Zookeeper를 대체하기 시작
ㄴ ElasticSearch가 또다른 예
ZooKeeper의 일반적인 사용 사례
ㄴ 메시지 큐를 위한 Apache Kafka
ㄴ 분산 데이터베이스 조정을 위한 Apache HBase
ㄴ 분산 스트림 처리를 위한 Apache Storm
Kafka 중요 개념
Producer, Broker, Consumer, Controller, Consumer Group
Producer:
ㄴ Producer는 데이터를 Kafka 클러스터로 보내는 주체
ㄴ 데이터를 생성하고, Kafka 주제(Topic)에 데이터를 게시
ㄴ Producer는 Kafka 브로커에 직접 연결하고 데이터를 전송
Broker:
ㄴ Kafka 클러스터의 중심적인 역할을 하는 브로커
ㄴ Broker는 데이터를 저장하고, 프로듀서로부터 데이터를 수신하며, 컨슈머에게 데이터를 전달
ㄴ 클러스터에는 여러 개의 브로커가 있을 수 있으며, 각각은 데이터의 일부를 저장하고 데이터를 복제하여 내구성과 가용성을 보장
Controller:
ㄴ Kafka 클러스터의 상태와 구성을 관리하는 컨트롤러
ㄴ 컨트롤러는 브로커 중 하나가 맡으며, 클러스터 상태의 일관성을 유지하기 위해 리더 선출, 파티션 재할당, 브로커 장애 감지 등을 처리
ㄴ 컨트롤러는 클러스터의 안정성과 가용성을 유지하기 위해 주기적으로 리더 선출과 장애 감지를 수행
Consumer:
ㄴ Consumer는 Kafka 클러스터에서 데이터를 읽는 주체
ㄴ Consumer는 주어진 주제의 파티션에서 데이터를 소비하며, 자신의 오프셋(offset)을 추적하여 읽은 데이터의 위치를 기록
ㄴ Consumer는 Kafka 브로커에 직접 연결하고, 데이터를 가져와 처리
Consumer Group:
ㄴ Consumer Group은 여러 개의 컨슈머를 그룹화하여 동일한 주제의 데이터를 병렬로 처리하는 데 사용
ㄴ Consumer Group 내의 컨슈머는 주제의 파티션을 공정하게 분배하여 데이터를 처리
ㄴ Consumer Group은 주어진 주제의 모든 파티션을 커버하기 위해 리밸런싱(rebalancing)을 수행하고, 컨슈머 간의 작업 부하를 분산
1. Kafka 클러스터에서는 프로듀서가 데이터를 생성하고, 브로커가 데이터를 저장하며, 컨슈머가 데이터를 읽어 처리
2. 컨트롤러는 클러스터의 구성과 안정성을 관리하고, 컨슈머 그룹은 데이터를 병렬로 처리하기 위해 컨슈머를 그룹화

Topics, Partitions, Segments
Topics:
Kafka에서 데이터는 주제(Topic) 단위로 구분됩
주제는 관련된 데이터 레코드의 카테고리 또는 카테고리 집합
프로듀서는 데이터를 특정 주제에 보내고, 컨슈머는 해당 주제에서 데이터를 읽음
Partitions:
Topic은 하나 이상의 파티션으로 나눠짐
각 파티션은 독립적으로 데이터를 저장하고 처리할 수 있는 단위
파티션은 순차적인 순서로 데이터를 저장하며, 각 파티션은 컨슈머 그룹의 여러 컨슈머에게 병렬로 처리
파티션은 일련의 오프셋(offset)으로 식별되며, 컨슈머는 각 파티션의 오프셋을 추적하여 읽은 데이터의 위치 (commit log)를 기록
Segments:
파티션은 세그먼트로 나눠짐
세그먼트는 파티션에 대한 데이터 파일로, 디스크에 저장되어 있음
세그먼트는 일정한 크기(기본적으로 1GB)에 도달하거나 시간 기반 설정에 따라 주기적으로 분리
분리된 세그먼트는 읽기 전용 상태로 전환되고, 새로운 데이터는 새로운 세그먼트에 저장
1. Kafka에서는 데이터를 주제에 보내면 해당 Topic은 여러 파티션으로 나뉘고, 각 파티션은 세그먼트로 분리되어 디스크에 저장
2. 컨슈머는 오프셋을 기반으로 파티션의 세그먼트에서 데이터를 읽어 처리

Topic
- Consumer가 데이터(Message)를 읽는다고 없어지지 않음
- Consumer별로 어느 위치의 데이터를 읽고 있는지 위치 정보를 유지함
- Fault Tolerance를 위해 이 정보는 중복 저장됨

Topic과 Partition와 Replication
- 하나의 Partition은 Fail-over를 위해 Replication Partition을 가짐
- 하나의 Partition에는 Leader와 Follower가 존재
ㄴ 쓰기는 Leader를 통해 하고 읽기는 모든 Leader와 Follower를 통해 함
Replication:
ㄴ Kafka는 데이터의 내구성과 가용성을 보장하기 위해 데이터를 여러 개의 브로커에 복제
ㄴ 각 파티션은 지정된 수의 복제본(Replica)을 가질 수 있음
ㄴ 복제본은 동일한 데이터를 저장하고 있으며, 주키퍼(ZooKeeper)를 통해 리더 선출과 복제본 간의 동기화를 관리
ㄴ 복제본은 장애 발생 시 데이터의 안정성을 유지하고, 높은 가용성을 제공
Leader와 Follower:
ㄴ 각 파티션은 복제본 중 하나가 리더(Leader)로 선택
ㄴ 리더는 해당 파티션에 대한 모든 쓰기와 읽기 요청을 처리
ㄴ 나머지 복제본은 팔로워(Follower)로서 리더의 변경사항을 복제하여 데이터의 일관성을 유지
ㄴ 만약 리더가 장애가 발생하면, 주키퍼를 통해 새로운 리더가 선출되고 복제본 중 하나가 새로운 리더가 됨

Partition과 Segment
- 하나의 Partition은 다수의 Segment로 구성됨
ㄴ Segment는 변경되지 않는 추가만 되는 로그 파일이라고 볼 수 있음 (Immutable, Append-Only)
ㄴ Commit Log
- 각 Segment는 디스크상에 존재하는 하나의 파일
- Segment는 최대 크기가 있어서 이를 넘어가면 새로 Segment 파일을 만들어냄
ㄴ 그래서 각 Segment는 데이터 오프셋 범위를 갖게 됨
ㄴ Segment의 최대 크기는 1GB 혹은 일주일치의 데이터

로그 파일의 특성 (Partition의 특성 => 정확히는 Segment의 특성)
- 항상 뒤에 데이터(Message)가 쓰여짐: Append Only
- 한번 쓰여진 데이터는 불변 (immutable)
- Retention period에 따라 데이터를 제거하기도 함
- 데이터에는 번호(offset)가 주어짐
Commit Log란?
- Sequential, Immutable, Append-Only
- WAL (Write Ahead Logging)
ㄴ 데이터 무결성과 신뢰성을 보장하는 표준 방식
ㄴ 데이터베이스에 대한 모든 변경 사항을 먼저 Commit Log라는 추가 전용 파일에 기록
- Replication과 Fault Tolerance의 최소 단위
- Data Recovery나 Replay에 사용 가능
Broker의 역할
- Topic은 다수의 시간순으로 정렬된 Message들로 구성
- Producer는 Topic을 먼저 생성하고 속성 지정
- Producer가 Message들을 Broker로 전송
- Broker는 이를 Partition으로 나눠 저장 (중복 저장)
ㄴ Replication Factor: Leader & Follower
- Consumer는 Broker를 통해 메세지를 읽음
- 하나의 Kafka 클러스터는 다수의 Broker로 구성됨
- 하나의 Broker는 다수의 Partition들을 관리/운영
- 한 Topic에 속한 Message들은 스케일을 위해 다수의 Partition들에 분산 저장
- 다수의 Partition들을 관리하는 역할을 하는 것이 Broker들
ㄴ 한 Broker가 보통 여러 개의 Partition들을 관리하며 이는 Broker가 있는 서버의 디스크에 저장됨
ㄴ Broker들 전체적으로 저장된 Partition/Replica의 관리는 Controller의 역할
- 하나의 Partition은 하나의 로그 파일이라고 볼 수 있음
ㄴ 각 Message들은 각기 위치 정보(offset)를 갖고 있음
- 이런 Message들의 저장 기한은 Retention Policy로 지정
Producer의 Partition 관리방법
- 하나의 Topic은 다수의 Partition으로 구성되며 이는 Producer가 결정
- Partition은 두 가지 용도로 사용됨
ㄴ Load Balancing
ㄴ Semantic Partitioning (특정 키를 가지고 레코드를 나누는 경우)
- Producer가 사용 가능한 Partition 선택 방법
ㄴ 기본 Partition 선택: hash(key) % Partition의 수
ㄴ 라운드 로빈: 돌아가면서 하나씩 사용
ㄴ 커스텀 Partition 로직을 구현할 수도 있음
Consumer 기본
- Topic을 기반으로 Message를 읽어들임 (Subscription이란 개념 존재)
- Offset를 가지고 마지막 읽어들인 Message 위치정보 유지
- Command Line Consumer 유틸리티 존재
- Consumer Group라는 개념으로 Scaling 구현
ㄴ Backpressure 문제 해결을 위한 방법
- Consumer는 다시 Kafka에 새로운 토픽을 만들기도 함
ㄴ 아주 흔히 사용되는 방법으로 하나의 프로세스가 Consumer이자 Producer 역할 수행
Kafka 기타 기능
Kafka Connect
Kafka Connect는 Kafka 위에 만들어진 중앙집중 데이터 허브
ㄴ 별도의 서버들이 필요하며 Kafka Connect는 별도의 오픈소스 프로젝트임
ㄴ 데이터 버스 혹은 메세지 버스라고 볼 수 있음
- 두 가지 모드가 존재
ㄴ Standalone 모드: 개발과 테스트
ㄴ Distributed 모드
데이터 시스템들 간의 데이터를 주고 받는 용도로 Kafka를 사용하는 것
ㄴ 데이터 시스템의 예: 데이터베이스, 파일 시스템, 키-값 저장소, 검색 인덱스 등등
ㄴ 데이터 소스와 데이터 싱크
Broker들 중 일부나 별개 서버들로 Kafka Connect를 구성
ㄴ 그 안에 Task들을 Worker들이 수행. 여기서 Task들은 Producer/Consumer 역할
ㄴ 외부 데이터(Data Source)를 이벤트 스트림으로 읽어오는 것이 가능
ㄴ 내부 데이터를 외부(Data Sink)로 내보내어 Kafka를 기존 시스템과 지속적으로 통합 가능
ㄴ 예: S3 버킷으로 쉽게 저장


Kafka Schema Registry
- Schema Registry는 Topic 메시지 데이터에 대한 스키마를 관리 및 검증하는데 사용
- Producer와 Consumer는 Schema Registry를 사용하여 스키마 변경을 처리

Serialization and Deserialization
Serialization (직렬화)
ㄴ 객체의 상태를 저장하거나 전송할 수 있는 형태로 변환하는 프로세스
ㄴ 보통 이 과정에서 데이터 압축등을 수행. 가능하다면 보내는 데이터의 스키마 정보 추가
Deserialization (역직렬화)
ㄴ Serialized된 데이터를 다시 사용할 수 있는 형태로 변환하는 Deserialization
ㄴ 이 과정에서 데이터 압축을 해제하거나 스키마 정보 등이 있다면 데이터 포맷 검증도 수행
Schema ID(와 버전)를 사용해서 다양한 포맷 변천(Schema Evolution)을 지원
ㄴ 보통 AVRO를 데이터 포맷으로 사용 (Protobuf, JSON)
포맷 변경을 처리하는 방법
ㄴ Forward Compatibility: Producer부터 변경하고 Consumer를 점진적으로 변경
ㄴ Backward Compatibility: Consumer부터 변경하고 Producer를 점진적으로 변경
ㄴ Full Compatibility: 둘다 변경
누가 메세지의 serialization과 deserialization을 담당? -> 보통 Kafka 관련 라이브러리

Kafka 아키텍처 - REST Proxy
- 클라이언트가 API 호출을 사용하여 Kafka를 사용 가능하게 해줌
ㄴ 메시지를 생성 및 소비하고, 토픽을 관리하는 간단하고 표준화된 방법을 제공
ㄴ REST Proxy는 메세지 Serialization과 Deserialization을 대신 수행해주고 Load Balancing도 수행
- 특히 사내 네트워크 밖에서 Kafka를 접근해야할 필요성이 있는 경우 더 유용

Kafka 아키텍처 - ksqlDB
- Kafka Streams로 구현된 스트림 처리 데이터베이스로 KSQL을 대체
ㄴ SQL과 유사한 쿼리 언어. 필터링, 집계, 조인, 윈도우잉 등과 같은 SQL 작업 지원
ㄴ 연속 쿼리: ksqlDB를 사용하면 데이터가 실시간으로 도착할 때 지속적으로 처리하는 연속 쿼리 생성 가능
ㄴ 지속 업데이트되는 뷰 지원: 실시간으로 지속적으로 업데이트되는 집계 및 변환 가능
- Spark에서 보는 것과 비슷한 추세: SQL이 대세
Kafka 설치
사용할 github repo : https://github.com/conduktor/kafka-stack-docker-compose
$ git clone https://github.com/conduktor/kafka-stack-docker-compose.git
$ cd kafka-stack-docker-compose
$ docker compose -f full-stack.yml up
ㄴ 컴퓨터 사양이 좋은 경우 full-stack.yml을 사용
ㄴ 아니면 zk-single-kafka-single.yml이나 zk-single-kafka-multiple.yml을 사용
Kafka 프로그래밍 옵션
Python -> Kafka-Python: 또다른 파이썬 기반 라이브러리
간단한 Producer 만들기

Python Lambda 함수
람다 함수는 흔히 이야기하는 함수형 언어(LISP, Haskell, …)에서는 기본 개념
ㄴ Imperative Programming (step-by-step): Python, C/C++, Java, …
ㄴ Functional Programming (수학 공식처럼 함수를 연결해서 계산): Erlang, Lisp,
ㄴ Declarative Programming (원하는 결과와 어디서 그걸 얻을지만 기술): SQL
파이썬에서 람다함수를 사용하는 경우는?
보통 higher-order 함수 (함수를 인자로 받는 함수)의 인자로 람다함수를 사용
ㄴ higher-order 함수의 예: map, filter, reduce, sorted… 앞의 value_serializer
ㄴ Pandas의 일부 함수들은 higher-order 함수: apply, assign, map, …
람다함수의 포맷:
ㄴ lambda arguments: expression
ㄴ 예) lambda x: dumps(x).encode('utf-8')
간단한 Producer 실행
먼저 카프카를 설치한 컨테이너가 작동되는지 확인

가상환경 하나 만들고 pip install kafka-python

위에서 만든 producer 실행

Kafka 웹 콘솔에서 Topic 생성 여부 확인

Consumer 객체 만들기

간단한 Consumer 만들기

Consumer 실행

'프로그래머스 데브코스-데이터 엔지니어 > TIL(Today I Learned)' 카테고리의 다른 글
| 07/14 70일차 Spark Streaming (0) | 2023.07.14 |
|---|---|
| 07/13 69일차 Kafka CLI, Topic, Consumer, ksqlDB (0) | 2023.07.13 |
| 07/11 67일차 Udemy의 데이터 처리 (0) | 2023.07.11 |
| 07/10 66일차 스트리밍 데이터 (0) | 2023.07.10 |
| 07/07 65일차 Spark EMR과 Spark 요약 (0) | 2023.07.07 |