CLI, Topic, Consumer, ksqlDB
주요 메모 사항
Kafka Client Tool
Kafka CLI Tools 접근 방법
docker ps를 통해 Broker의 Container ID 혹은 Container 이름 파악
해당 컨테이너로 로그인
ㄴ $ docker exec -it Broker_Container_ID sh
거기서 다양한 kafka 관련 클라이언트 툴을 사용 가능
ㄴ kafka-topics
ㄴ kafka-configs
ㄴ kafka-console-consumer
ㄴ kafka-console-producer
docker 컨테이너 접속
kafka1의 이름을 가진 컨테이너가 Broker

kafka-topics
$ kafka-topics --bootstrap-server kafka1:9092 --list
$ kafka-topics --bootstrap-server kafka1:9092 --delete --topic topic_test

kafka-console-producer
Command line을 통해 Topic 만들고 Message 생성 가능
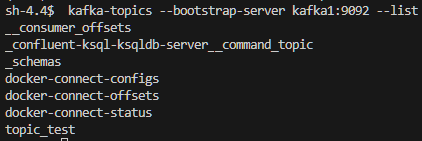
$ kafka-console-producer --bootstrap-server kafka1:9092 --topic test_console
kafka-console-consumer
Command line을 통해 Topic에서 Message 읽기 가능
--from-beginning 옵션이 있으면 처음부터 읽음 (earliest). 아니면 latest로 동작
$ kafka-console-consumer --bootstrap-server kafka1:9092 --topic test_console --from-beginning
두 Console 프로세스들의 Side-by-side 실행
터미널을 하나 열고 동일 Broker 로그인 후 console-producer로 메세지 발생
왼쪽 Producer
$ kafka-console-producer --bootstrap-server kafka1:9092 --topic test_console
오른쪽 Consumer
$ kafka-console-consumer --bootstrap-server kafka1:9092 --topic test_console

Topic의 메세지들을 Web에서 볼 수 있음
Topic 파라미터 설정
Topic과 관계된 파라미터들을 KafkaProducer를 통해 설정
Topic 생성시 다수의 Partition이나 Replica를 주려면
- 먼저 KafkaAdminClient 오브젝트를 생성하고 create_topics 함수로 Topic을 추가
- create_topics의 인자로는 NewTopic 클래스의 오브젝트를 지정

NewTopic 클래스

Kafka Producer 동작

KafkaProducer로 토픽 만들기
랜덤하게 사람 정보를 만들어서 저장하는 Kafka Producer를 구현
ㄴ Faker라는 모듈 사용: pip3 install faker
ㄴ pydantic의 BaseModel을 사용하여 메세지 클래스를 구현 (Person)
ㄴ pip3 install pydantic
ㄴ 이번에는 Topic을 먼저 만들고 진행
pip install

설치가 완료되면 fake_person_producer 실행

Web UI
Consumer 옵션 살펴보기
KafkaConsumer 파라미터
Topic 이름을 KafkaConsumer의 첫 번째 인자로 지정 혹은 나중에 별도로 subscribe를 호출해서 지정
Consumer가 다수의 Partitions들로부터 어떻게 읽나?
Consumer가 하나이고 다수의 Partitions들로 구성된 Topic으로부터 읽어야한다면?
ㄴ Consumer는 각 Partition들로부터 라운드 로빈 형태로 하나씩 읽게 됨
ㄴ 이 경우 병렬성이 떨어지고 데이터 생산 속도에 따라 Backpressure가 심해질 수 있음
ㄴ 이를 해결하기 위한 것이 뒤에 이야기할 Consumer Group
- 컨슈머 그룹 설정:
- 여러 컨슈머로 구성된 컨슈머 그룹을 생성합니다.
- 컨슈머 그룹은 동일한 주제에 대해 데이터를 병렬로 처리하기 위해 사용됩니다.
- 각 컨슈머 그룹은 주제의 파티션을 공정하게 분배받아 처리합니다.
- 파티션 할당 (Partition Assignment):
- 컨슈머 그룹이 주제의 데이터를 처리하기 위해 파티션을 할당받습니다.
- 할당 과정은 Kafka 클러스터의 컨트롤러에 의해 조정됩니다.
- 할당된 파티션은 각 컨슈머에게 균등하게 분배되어 데이터를 처리합니다.
- 할당된 파티션은 해당 컨슈머의 오프셋을 추적하여 읽은 데이터의 위치를 기록합니다.
- 데이터 읽기:
- 각 컨슈머는 할당받은 파티션에서 데이터를 읽습니다.
- 컨슈머는 각 파티션의 리더로부터 데이터를 읽게 됩니다.
- 컨슈머는 오프셋을 기반으로 데이터의 읽기 위치를 추적하여, 이전에 읽은 데이터 다음부터 읽어나갑니다.
- 컨슈머는 일정한 주기로 Kafka 브로커에게 오프셋을 커밋하여 읽은 위치를 기록합니다.
한 프로세스에서 다수의 Topic을 읽는 것 가능
ㄴ Topic 수만큼 KafkaConsumer 인스턴스 생성하고 별도의 Group ID와 Client ID를 지정해야함
Consumer Group이란?
- Consumer가 Topic을 읽기 시작하면 해당 Topic내 일부 Partition들이 자동으로 할당됨
- Consumer의 수보다 Partition의 수가 더 많은 경우, Partition은 라운드 로빈 방식으로 Consumer들에게 할당됨 (한 Partition은 한 Consumer에게만 할당됨)
ㄴ 이를 통해 데이터 소비 병렬성을 늘리고 Backpressure 경감
ㄴ 그리고 Consumer가 일부 중단되더라도 계속해서 데이터 처리 가능
- Consumer Group Rebalancing
ㄴ 기존 Consumer가 무슨 이유로 사라지거나 새로운 Consumer가 Group에 참여하는 경우 Partition들이 다시 지정이 되어야함. 이를 Consumer Group Rebalancing이라고 부르면 이는 Kafka에서 알아서 수행해줌
autocommit_consumer.py : Offset Auto Commit이 True

manualcommit_consumer.py : Offset Auto Commit이 False

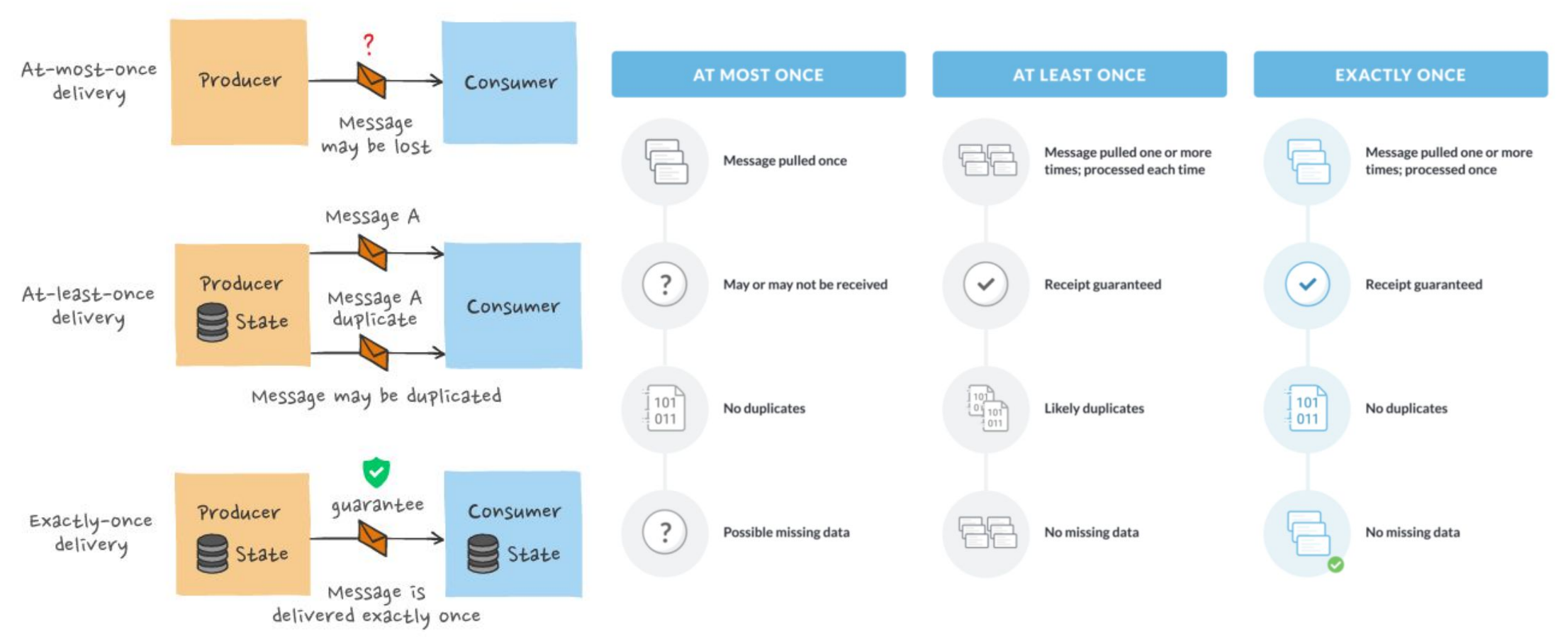
Message Processing Guarantee 방식
실시간 메시지 처리 및 전송 관점에서 시스템의 보장 방식에는 크게 3가지가 존재
위에서부터 아래로 갈수록 쉬워짐
| 방식 | 설명 |
| Exactly Once | Exactly Once('정확히 한 번')는 각 Message가 Consumer에게 정확히 한 번만 전달된다는 것을 보장. ㄴ > 네트워크 문제, 장애 또는 재시도 가능성으로 아주 어려운 문제. 1> Producer 단에서는 enable_idempotence를 True로 설정 2> Producer에서 메세지를 쓸 때와 Consumer에서 읽을 때 Transaction API를 사용 |
| At Least Once | At Least Once ('적어도 한 번 이상')는 모든 메시지가 Consumer에게 적어도 한 번 이상 전달되도록 보장하지만, 메시지 중복 가능성 존재. 이 경우 Consumer는 중복 메시지를 처리하기 위해 중복 제거 메커니즘을 구현해야함 (멱등성). ㄴ 이는 보통 Consumer가 직접 오프셋을 커밋을 할때 발생함. |
| At Most Once | At Most Once ('최대 한 번만')는 메시지 손실 가능성에 중점을 둠. 이는 메시지가 손실될 수는 있지만 중복이 없음을의미 가장 흔한 메시지 전송 보장 방식 (기본 방식) |
Consumer/Producer 패턴
- 많은 경우 Consumer는 한 Topic의 메세지를 소비해서 새로운 Topic을 만들기도함
- 즉 Consumer이면서 Producer로 동작하는 것이 아주 흔한 패턴임
- 데이터 Transformation, Filtering, Enrichment
ㄴ 동일한 프로세스 내에서 Kafka Consumer를 사용하여 한 Topic에서 메시지를 읽고 필요한 데이터 변환 또는 Enrichment을 수행한 다음, Producer를 사용하여 수정된 데이터를 다른 Topic으로 푸시 가능
ksqlDB 사용
- REST API나 ksql 클라이언트 툴을 사용해서 Topic을 테이블처럼 SQL로 조작
- 여기서는 ksql을 사용하는 간단한 데모
ㄴ docker ps 후 confluentinc/cp-ksqldb-server의 Container ID 복사
ㄴ docker exec -it ContainerID sh


- ksql 실행후 아래 두 개의 명령 실행
ㄴ CREATE STREAM my_stream (id STRING, name STRING, title STRING) with (kafka_topic='fake_people', value_format='JSON');
ㄴ SELECT * FROM my_stream;




'프로그래머스 데브코스-데이터 엔지니어 > TIL(Today I Learned)' 카테고리의 다른 글
| 07/17 71일차 머신러닝 기초 (0) | 2023.07.17 |
|---|---|
| 07/14 70일차 Spark Streaming (0) | 2023.07.14 |
| 07/12 68일차 Kafka (0) | 2023.07.12 |
| 07/11 67일차 Udemy의 데이터 처리 (0) | 2023.07.11 |
| 07/10 66일차 스트리밍 데이터 (0) | 2023.07.10 |